


Current situation
Traditional ECM platforms store “enterprise content” in a file system. Although they usually provide some form of “connectors/adapters” for storing content in other types of storage, like object storage, this is mainly an afterthought, not an initial design choice. This approach has many areas for improvement, as we will point out in this blog post.
Traditional approaches
Traditional ECM systems have three main infrastructural parts:
- Content (Documents) Store
- Metadata Store
- Search Service
Historically, the first implementations tried to minimize complexity by using only RDBMS (Relational Database Management System) for all three purposes.
In that case, “content” is stored in some kind of BLOB (Binary Large Object) column and content metadata as fields in custom-tailored database tables. Search services are implemented as SQL queries on “metadata” columns. Although simple, that approach soon became “too simple.” In the enterprise context, storing many documents in RDBMS burdens the database too much.
A large number of different “content types” usually required different, complex database schemas for transacting (ingesting) and, at the same time, searching for different “content types.” The next generation of ECMs has tried to overcome those problems by “ditching out” content from DBs into a “file system” and keeping only the pointer (“id”) of the content in the DB.
Similarly, for scaling the “search,” Lucene-based solutions like SOLR and Elastic Search become standard practice instead of direct searches on the DB tables. Some main drivers of using ECMs, like granular security over the content and content versioning, are realized by hiding content (files) behind provider-specific APIs that “simulate” required features that file systems do not provide out-of-the-box.
In that scenario, RDBMS is often used to store additional tables (access rights tables, document versions tables, etc.).
Object storage
Cloud providers have realized from the beginning that the requirements for storing BLOBs differ significantly from those of traditional file systems. A canonical example is Amazon S3 object storage.
Object storage systems have different characteristics compared to file systems. They should be seen as “key-value stores” where the value is some BLOB (Binary Large OBject) (content in the context of the ECM).
Such systems typically do not support file system features like random writes and hierarchical organization (directories). When content changes, we rewrite the whole object.
It is essential to notice that file-system features are typically not required in the ECM context, where we need versioning instead of editing, and requirements to organize content (files) in a hierarchical structure are rather a constraint than a feature in that context.
Relieved from “file system constraints,” object stores are typically more performant, especially in cloud/distributed systems.
For example, traditional ECM systems invent some artificial hierarchy, e.g. (year/month/date/hour…J) to avoid problems accessing directories with too many files. Additionally, they simulate file versions with different files “linked” with some custom application logic. Some standard features of “object storages,” like immutability, retention schedules, etc., are typical additional custom applications/modules (usually under the “Record Management” banner).
S3 as an industry standard
With the emergence of the “Cloud,” object storage became widely used.
Amazon S3 quickly became an industry standard for object storage in the cloud. In this post, we will not discuss the benefits of storing content in the cloud; many such analyses are readily available. Here, we are interested in using such storage in the “next generation” of ECM systems.
Why do we call S3 a standard? Although there is no official standard/body/process for Amazon S3 object storage currently, there is little doubt that S3 is the main player in this area.
For example, Gartner, in the “Magic Quadrant for Distributed File Systems and Object Storage,” under the “Standard capabilities,” categorizes “RESTful HTTP APIs such as Amazon S3.”
It is essential to mention what is “standard” in that “requirement” – “RESTful HTTP API”!
Remember that traditional ECM systems have proprietary APIs for accessing content. Transitioning between ECM vendors usually requires custom projects and expert knowledge of both platforms (export/import).

Content is yours
“File over app is a philosophy: if you want to create digital artifacts that last, they must be files you can control, in formats that are easy to retrieve and read. Use tools that give you this freedom. “
It is important to know that customer content in traditional ECM systems is locked under the provider’s application-specific API or, worse, the provider’s ECM application.
In S3-compatible systems, you only need the URI of your content and access permissions.
The standard REST API call returns content metadata (standard and custom(er) specific). Such URI (Uniform Resource Identifier) is based on the single “key” property of your required content (Object storage is a “key-value” store), so you do not need to know the location in the directory tree. If you use versioning, you extend the URL with the version number, simple as that.
If we step back for a minute to see a bigger picture, by only storing the content in the S3 compatible storage, we have a large chunk of ECM functionalities “out of the box”, and we do not need a box if we do not want to ;):
- “standard” REST API – your content is accessible even with the web browser only
- standard and custom properties “attached” to the content
- rich security model
- versioning
- retention/disposition schedules
- cloud-ready
What modern ECM should be built upon
One might wonder if S3 compatibility gives us so many “standard ECM” capabilities OTB do we need ECM at all.
Of course, we need to solve our customer’s business problems, not patch up “file system” deficiencies.
Our customer needs modern “purpose-built” interfaces and integration with their value-added business processes where their competitive advantages really are.
How are we going to build such applications?
For developers, S3-compatible object stores offer “polyglot APIs” for the most popular programming languages, so we do not need to use REST API if we do not want to. Those APIs are used by millions of developers and tested/enhanced/optimized in the process.

What about metadata?
At the beginning of this post, we have emphasized three main components of the ECM system:
- Content (Documents) Store
- Metadata Store
- Search Service
S3 compatible storage solves 1) well. Regarding metadata, one of the selling points of traditional ECMs is “attaching” custom metadata to the content. S3 storages support custom metadata, but those metadata are not dynamic enough to meet typical ECM requirements.
S3 metadata are written at the moment of the content’s creation and are not meant to be updatable.
A typical use case for ECM is to have some dynamic (status-like) property/metadata on the content. So, we still need some metadata storage that supports efficient metadata updates.
Keeping metadata in the RDBMS is still a viable option, although it is worth considering that we typically track some kind of events on the content. The events-storage scenario is a potential theme for another blog post.
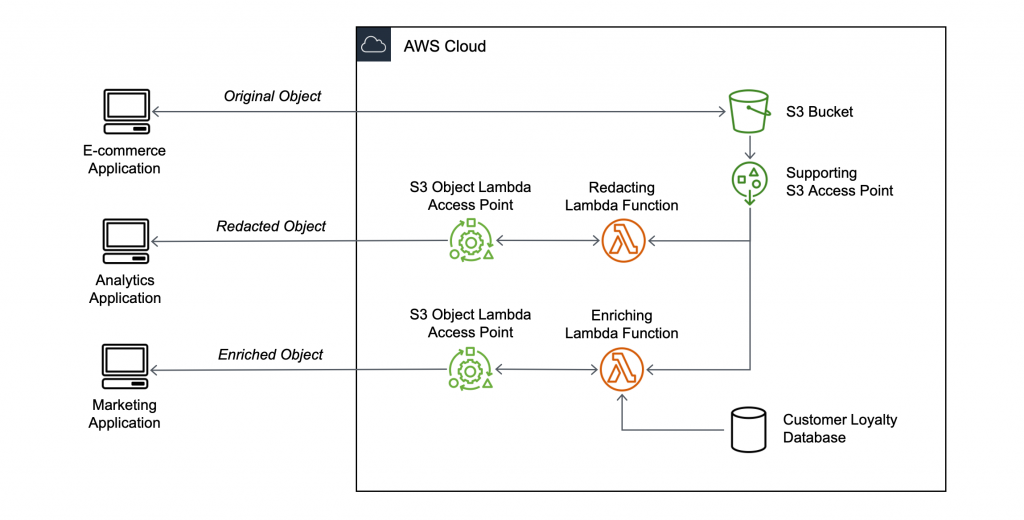
This use-case of joining metadata written with content with additional (“dynamic”) metadata is so typical that S3 compatible platforms usually support/document such scenarios in the tutorials:
Tutorial:
Notice that, like in the above picture, you can integrate the metadata source with your implementation.
What about search?
At the beginning of this blog post, we mentioned that RDBMs are rarely used for search, even in traditional ECMs. They usually maintain an external (Elastic/SOLR) index for that purpose.
This component has minimal change compared to traditional ECM. We have several potential scenarios: Use “search service” as an index for a more efficient/scalable search engine to point to metadata from another store (e.g., RDBMS) or use the search engine as a metadata store in the first place.
Cloud Only? Not anymore.
Often, we perceive S3-compatible storage as a cloud solution only.
However, many customers want to store their content on their premises for various reasons.
We have highly established vendors; one of them undoubtedly worth mentioning is MINIO, which provides S3-compatible storage on-premises or in “any” cloud.
We believe there is no practical reason for the modern ECM to continue storing blobs/objects in a file system. We do not use them as files in ECM, so why store them as such?
About the author
Ivan Listeš is an experienced “Solution Architect” and “Software Development Lead” for ECM and BPM solutions.

Leverage the expertise of over 200 professionals to optimize your business
Start now


{kind=link}